
SEO-Embeddings: So nutzt ihr sie für bessere Rankings

Wenn ihr euch mit moderner Suchtechnologie oder Künstlicher Intelligenz beschäftigt, stoßt ihr immer öfter auf den Begriff Embeddings. Diese Methode steckt hinter vielen aktuellen Entwicklungen – von Sprachmodellen wie ChatGPT bis hin zu personalisierten Suchergebnissen. Statt Inhalte nur über exakte Wortübereinstimmungen zu vergleichen, ermöglichen Embeddings eine Analyse auf Bedeutungsebene. Das verändert nicht nur, wie Maschinen Informationen verarbeiten, sondern auch, wie ihr Inhalte strukturieren und auffindbar machen könnt. In diesem Beitrag erfahrt ihr zunächst, was Embeddings sind, welche Rolle sie in großen Sprachmodellen spielen und wie sich dieses Konzept später gezielt im SEO einsetzen lässt.
Einführung in Embeddings
Embeddings sind mathematische Repräsentationen von Inhalten. Ein Wort, ein Satz, ein Bild oder ein ganzes Dokument wird in einen Vektor übersetzt – eine geordnete Liste von Zahlen. Diese Zahlen codieren Bedeutung und Kontext. Inhalte, die sich semantisch ähneln, liegen im Vektorraum nah beieinander, Inhalte ohne Bezug liegen weiter auseinander.
Früher wurden Texte vor allem über exakte Übereinstimmungen von Zeichen verglichen. Embeddings ermöglichen den Vergleich über Bedeutung. Das ist die Grundlage dafür, dass Maschinen nicht nur Zeichenketten, sondern Zusammenhänge verstehen.
Typische Einsatzbereiche in der KI sind die Ähnlichkeitssuche für Texte, Bilder und Audio, Empfehlungssysteme für Artikel, Produkte und Videos, das Clustering und die Themenanalyse in großen Content-Sammlungen sowie die Erkennung von Dubletten oder semantischen Entitäten.
Stellt euch vor: Wenn ihr „Apfel“, „Birnen“ und „Obst“ betrachtet, liegen die Vektoren von „Apfel“ und „Birne“ näher beieinander als „Apfel“ und „Schraubenzieher“. Der Oberbegriff „Obst“ befindet sich in einer ähnlichen Region wie Apfel und Birne, obwohl das Wort selbst anders aussieht. Diese räumliche Nähe bildet Bedeutung ab.
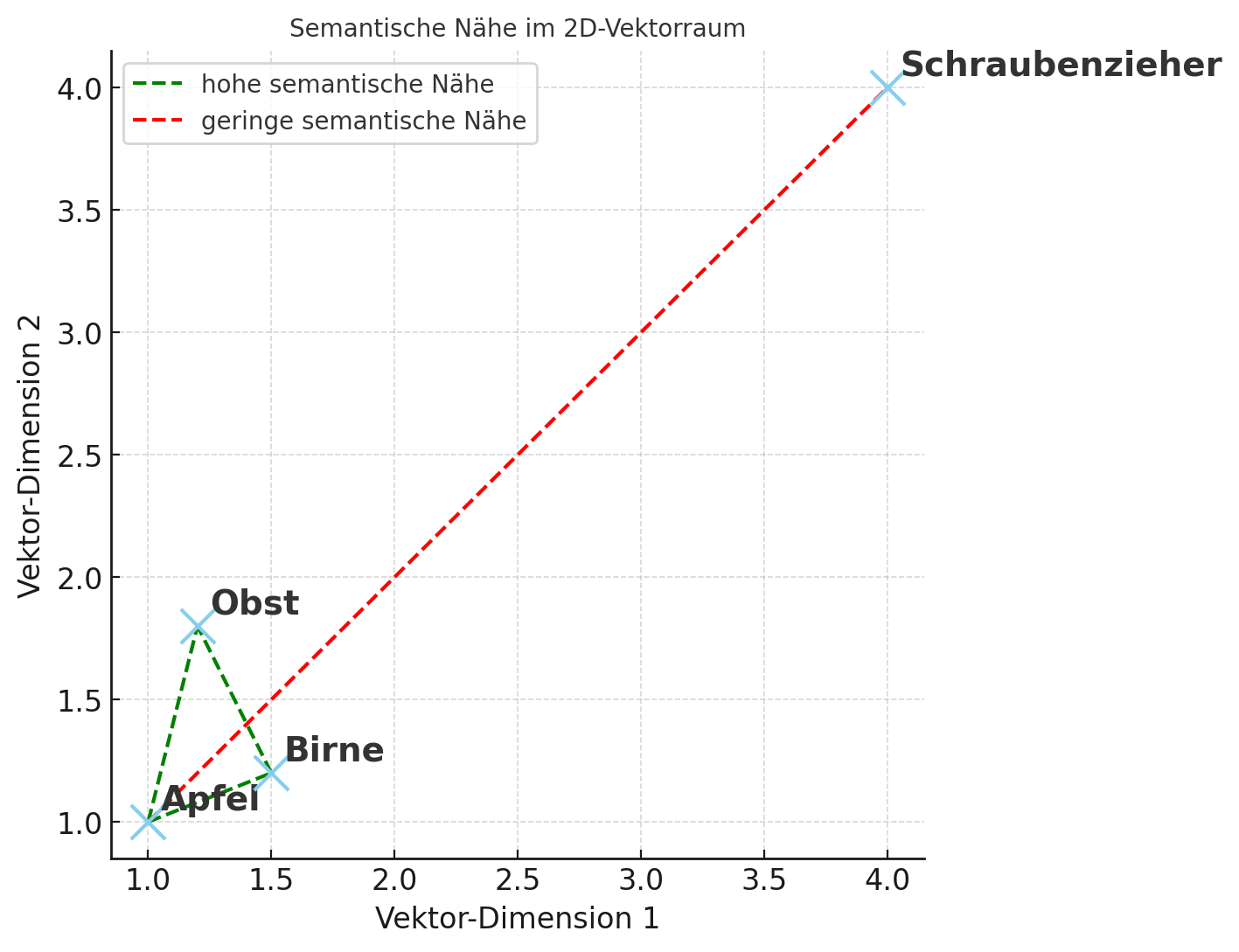
Hier das obenstehende Beispiel einmal schematisch dargestellt. Die zweidimensionale Darstellung ist dabei nur eine Vereinfachung – eigentlich nutzen Vektordatenbanken mehrdimensionale Räume zur Speicherung.
Hinweis: Das Bild wurde KI-generiert
Embeddings und LLMs
Large Language Models nutzen Embeddings, um Sprache zu verstehen und Wissen zu organisieren. Sie helfen beim Verarbeiten des Eingabetextes, beim Abbilden von Kontext und beim gezielten Abrufen von Informationen aus internen oder externen Wissensquellen.
Wichtige Rollen von Embeddings in LLMs:
Token-Repräsentation: Wörter und Teilwörter werden als Vektoren eingebettet, damit das Modell Muster in Sprache erkennt.
Kontextverständnis: Sätze und Absätze erhalten semantische Repräsentationen, die Beziehungen zwischen Themen erfassen.
Retrieval-Augmentation: Dokumente werden als Vektoren gespeichert, um später relevante Passagen gezielt zu finden.
Semantische Beziehungen erkennt ihr daran, dass Synonyme nahe beieinanderliegen, dass sich Fachbegriffe aus einer Domäne gruppieren und dass mehrdeutige Wörter je nach Kontext eine andere Position im Vektorraum erhalten.
Sobald ihr Inhalte, Fragen oder Nutzerinteressen als Embeddings vorliegen habt, könnt ihr ihre semantische Nähe messen. Das eröffnet euch viele Möglichkeiten, Inhalte zu strukturieren, neue Themen zu entdecken und passende Inhalte auszugeben.
Übergang zum SEO-Kontext
Die Grundidee von Embeddings ist unabhängig von Suchmaschinen. Da Suchmaschinen Inhalte jedoch nach Relevanz ordnen, ist semantisches Verständnis entscheidend. Moderne Suche nutzt Embeddings, um Beziehungen zwischen Suchanfragen und Dokumenten zu bewerten. Für euch heißt das: Wenn ihr Inhalte so plant und analysiert, dass semantische Nähe sichtbar wird, könnt ihr die Suchintention besser treffen.
Einsatzmöglichkeiten von Embeddings in der SEO
Keyword-Clustering und Informationsarchitektur
Statt hunderte Keywords in Tabellen zu verwalten, könnt ihr mit Embeddings Suchanfragen nach semantischer Nähe gruppieren. Das Ergebnis sind Themencluster, in denen Hauptthemen, Unterthemen und unterstützende Inhalte klar erkennbar werden. Das erleichtert euch die Planung eurer Seitenstruktur: Ein zentrales Thema bekommt eine Hauptseite, ergänzende Inhalte werden als Unterseiten oder Blogbeiträge angelegt. So entsteht eine klare Informationsarchitektur, die Suchmaschinen und Nutzenden Orientierung gibt.
Themenlücken erkennen
Mit Embeddings könnt ihr eure bestehenden Inhalte mit dem thematischen Raum eines Keywords vergleichen. Stellt euch vor, ihr habt bereits zehn Artikel zu „Content-Marketing“. Ein semantischer Vergleich zeigt euch, ob wichtige Unterthemen wie „Buyer Personas“ oder „Content-Distribution“ fehlen. So könnt ihr gezielt neue Inhalte produzieren, die die thematische Abdeckung eurer Website vervollständigen.
Bessere interne Verlinkung
Indem ihr Beiträge nach semantischer Nähe sortiert, seht ihr sofort, welche Inhalte thematisch gut zusammenpassen. Das hilft euch dabei, Lesenden mit eurem Linkbuilding einen tatsächlichen Mehrwert zu bieten. Anstatt wahllos zu verlinken, führt ihr Nutzende gezielt zu weiterführenden Inhalten. Gleichzeitig stärkt ihr thematische Signale gegenüber Suchmaschinen.
Personalisierte Ergebnisse und Nutzererfahrung (UX)
Wenn ihr Embeddings einsetzt, könnt ihr Inhalte individuell auf die Absichten der Nutzenden zuschneiden. Erkennt das System, dass ein:e Nutzer:in nach praxisnahen Beispielen sucht, bekommt diese Person direkt die passenden Inhalte vorgeschlagen. Das steigert die Zufriedenheit und die Wahrscheinlichkeit, dass Inhalte länger konsumiert oder geteilt werden.
Entitäten und Synonyme
Embeddings erkennen nicht nur exakte Begriffe, sondern auch Synonyme und verwandte Konzepte. Das ist hilfreich für Glossare, strukturierte Daten oder FAQ-Bereiche. Ein Beispiel: Sucht jemand nach „KI im Marketing“, könnt ihr automatisch auch Inhalte zu „Künstliche Intelligenz im Marketing“ oder „AI Marketing Tools“ anbieten.
Vorteile und Grenzen
Vorteile
Relevanzbewertung auf Bedeutungsebene: Ihr erkennt, ob Inhalte inhaltlich wirklich zueinander passen, auch wenn sie unterschiedliche Wörter nutzen.
Bessere Themenabdeckung: Cluster helfen euch, nicht nur einzelne Keywords zu bedienen, sondern komplette Themenfelder abzudecken.
Effiziente Suche in großen Archiven: Gerade bei umfangreichen Blogs oder Content-Datenbanken spart ihr Zeit, wenn ähnliche Inhalte schnell gefunden werden.
Robustheit gegenüber Schreibvarianten: Embeddings erkennen Zusammenhänge auch bei Tippfehlern oder abweichenden Schreibweisen.
Grenzen
Qualität der Trainingsdaten: Sind die Daten, auf denen die Embeddings beruhen, unvollständig oder fehlerhaft, wirkt sich das direkt auf die Ergebnisse aus.
Fachliche Prüfung notwendig: Die mathematische Nähe bedeutet nicht automatisch fachliche Relevanz. Ihr müsst die Ergebnisse immer inhaltlich validieren.
Rechenaufwand: Bei sehr großen Datenmengen können Berechnungen rechenintensiv und damit zeitaufwendig sein.
Google: Auf Embeddings optimieren gleicht Keyword Stuffing
SEOSüdwest hat ein Statement von Googles John Müller aufgegriffen, die Optimierung von Inhalten für die Embeddings von Suchmaschinen gleiche Keyword Stuffing. Bei näherer Betrachtung macht das Sinn: Wenn ihr zu viele verwandte Themen und Keywords in euren Content aufnehmt, nur um den Algorithmen der Suchmaschinen zu gefallen, entstehen sehr wahrscheinlich wenig leserfreundliche Beiträge.
Ihr solltet euch immer die Frage stellen, ob eine Verlinkung auf ein verwandtes Thema oder das Umreißen von einem ähnlichen Gebiet wirklich sinnhaft für eure Leser:innen ist. Das ist meistens nur dann der Fall, wenn sich die Erwähnung natürlich in den Inhalt einfügt. Ist das nicht der Fall, könnt ihr euch die Ergänzung im Grunde sparen – sie passt semantisch ohnehin nicht in euren Content.
Tipp: Erstellt eure eigene Vektordatenbank mit Pinecone
Google & Co. setzen immer stärker Verktordatenbanken für die semantische Suche ein. Dabei verliert das einzelne Keyword mehr und mehr an Bedeutung. Daher macht es total Sinn, wenn ihr eine eigene Vektordatenbank für eure SEO-Strategie einsetzt. Dabei könnt ihr auf Tools zurückgreifen, die die mathematische Umrechnung für euch übernehmen. Eines dieser Tools ist Pinecone, das gerne in Verbindung mit Automatisierungstools wie n8n genutzt wird. Der Dienst ist deshalb so beliebt, weil ihr bereits kostenlos mit Pinecone starten könnt. Dabei gibt es zwar regionale Einschränkungen, was das Server-Hosting von Pinecone anbelangt, solange ihr nur unsensible Daten, wie z. B. Keywords, in euren Datenbanken verwendet, ist das aber unkritisch.
Es würde den Rahmen dieses Beitrages sprengen, zu erklären, wie ihr Pinecone installiert und eine Datenbank mit dem Tool aufsetzt. Dazu existieren aber zahlreiche Tutorials im Web. Wir empfehlen euch, dabei auf Video-Tutorials via YouTube zurückzugreifen, da die Thematik so anschaulicher und greifbarer ist.
Alternativen zu Pinecone:
Weaviate: Open-Source-Vektordatenbank mit integrierten Modulen für semantische Suche, Filterung und hybride Abfragen.
Milvus: Skalierbare Open-Source-Vektordatenbank, optimiert für große Datensätze und schnelle Suche.
Zilliz Cloud: Gehostete Cloud-Version von Milvus mit einfacher Verwaltung und Skalierbarkeit.
Vespa.ai: Plattform für große Such- und Empfehlungssysteme mit Vektor- und Textsuche.
Marqo: API-basierter Service für semantische Suche mit Unterstützung für Text- und Bild-Embeddings.
FAISS: Open-Source-Bibliothek von Meta für schnelle Ähnlichkeitssuche in großen Vektorbeständen.
Schritt für Schritt: So erstellt ihr Cluster für die semantische Suche
Themen festlegen: Entscheidet zuallererst, für welche Themenfelder ihr Cluster bilden wollt. Es sollte ein allgemeines Oberthema geben, dass sich durch weiterführende Themen vertiefen lässt. Die Zuordnung ist nicht immer einfach und sicher auch ein wenig subjektiv: Manchmal kann ein Thema auch für mehrere Cluster genutzt werden. So könnte beispielsweise das Thema „Online-Marketing“ durch „Social Media“ ergänzt werden. „Social Media“ könnte aber ebenso gut ein eigenständiges Cluster sein.
Datengrundlage wählen: Nutzt Keywords, Titel, Zwischenüberschriften oder Textauszüge. Je sauberer und thematisch passender eure Ausgangsdaten sind, desto besser die Ergebnisse.
Daten bereinigen: Entfernt Duplikate, vereinheitlicht Schreibweisen und achtet auf eine konsistente Sprache. Das verhindert, dass falsche Ähnlichkeiten entstehen.
Embeddings erzeugen und Ähnlichkeiten berechnen: Nutzt ein passendes Modell, zum Beispiel das oben beschriebene Pinecone, um eure Texte in Vektoren zu übersetzen, und berechnet deren Abstände. Daraus könnt ihr Cluster ableiten oder Empfehlungen generieren.
Ergebnisse prüfen und umsetzen: Bewertet die Cluster oder Vorschläge kritisch. Passt eure Content-Struktur, Themenplanung oder Verlinkung auf Basis dieser Erkenntnisse an.
Erfolg messen: Beobachtet, wie sich Sichtbarkeit, Klicks und Nutzungsverhalten entwickeln. Wiederholt den Prozess in regelmäßigen Abständen, um aktuell zu bleiben.
Fazit
Embeddings sind weit mehr als ein technisches Detail moderner KI – sie sind ein Schlüssel, um Inhalte auf Bedeutungsebene zu verstehen und gezielt miteinander zu verknüpfen. Für SEO eröffnet das neue Möglichkeiten: Statt nur auf einzelne Keywords zu optimieren, könnt ihr ganze Themenfelder abdecken, interne Verlinkungen strategisch aufbauen und Content so strukturieren, dass er Suchintentionen präzise erfüllt. Wer Embeddings in den eigenen SEO-Workflow integriert, kann nicht nur Rankings verbessern, sondern auch die Nutzererfahrung spürbar steigern. Die Kombination aus semantischer Tiefe und datengetriebener Analyse wird in Zukunft ein entscheidender Vorteil im Wettbewerb um Sichtbarkeit sein.
Häufig gestellte Fragen zu Embeddings in der SEO
Was sind Embeddings in einfachen Worten?
Embeddings sind Listen aus Zahlen, die die Bedeutung von Wörtern, Sätzen oder ganzen Texten in einem mathematischen Raum abbilden. Je ähnlicher sich zwei Inhalte in ihrer Bedeutung sind, desto näher liegen ihre Vektoren in diesem Raum. So können Maschinen Zusammenhänge erkennen, auch wenn unterschiedliche Begriffe verwendet werden.
Worin unterscheiden sich Embeddings von klassischen Keywords?
Keywords sind reine Zeichenfolgen, die exakt so in einem Text vorkommen müssen, um eine Übereinstimmung zu finden. Embeddings dagegen erfassen die Bedeutung und den Kontext eines Begriffs, sodass auch Synonyme und thematisch verwandte Inhalte erkannt werden. Dadurch sind sie flexibler und näher an der menschlichen Sprachwahrnehmung.
Wie hängen Embeddings und semantische Suche zusammen?
Die semantische Suche nutzt Embeddings, um den Sinn einer Suchanfrage und von Inhalten zu verstehen. Anstatt nur ähnliche Wörter abzugleichen, werden inhaltliche Zusammenhänge berücksichtigt. Das ermöglicht präzisere und relevantere Suchergebnisse.
Welche Daten eignen sich für die Erstellung eigener Vektordatenbanken?
Gut geeignet sind alle Textelemente, die semantische Signale tragen, wie Suchanfragen, Seitentitel, Zwischenüberschriften oder kurze Auszüge. Auch FAQ-Fragen und deren Antworten lassen sich einbetten, um thematische Zusammenhänge zu erkennen. Wichtig ist, dass die Daten sauber strukturiert und thematisch konsistent sind.